A survey addressed to users, creators, maintainers, and developers of biological databases revealed that specialized training and additional knowledge about diversity criteria are required. Based on our findings, we raise awareness of sample bias problems and provide a list of recommendations for enhancing biomedical research practices
Abstract
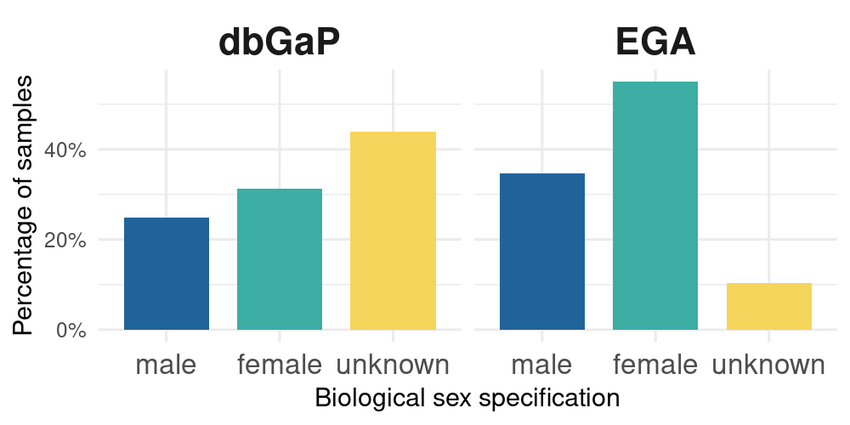
This paper focuses on the relevance of variables such as sex, age, or race for tailored treatments for precision medicine and the use of said variables on clinical studies and sample records. When these fields are not specified, it can result in biased predictions as they will not be considered in the training of the AI algorithm. In this work we quantified biases in sex classification over time in human data from studies deposited in EGA and the database of Genotypes and Phenotypes (dbGaP), which represents the EGA’s equivalent in the USA. The main result is that the EGA policy is effective to fight sex classification biases because there are significantly less samples classified as unknown after 2018 in this repository than in dbGaP. Additionally, we qualitatively assessed public opinion on this issue.